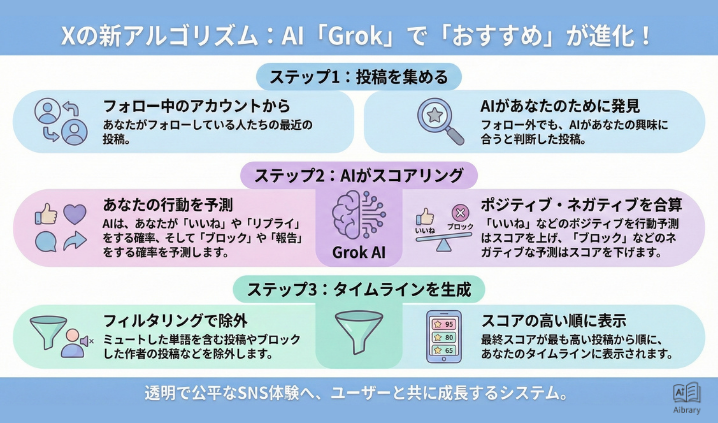
AIの「福祉」を考慮した初の試み。Claude“自ら対話を終える”新機能を搭載

生成AIの開発企業アンソロピック(Anthropic)は、最新の大規模言語モデルClaude Opus 4および4.1に、新たな対話制御機能を搭載した。極端な有害行動がユーザー側から持続された場合、モデル自身が対話の継続を拒否し、自発的に終了するという。
この機能は、Anthropicが進める「モデル福祉(model welfare)」という研究的枠組みに基づくもの。AIモデルを人間のように“擬人化”する意図はないとしながらも、仮にAIに内面的なストレスや道徳的反応があり得るならば、それに配慮した設計が必要だという考えから導入された。
出典:https://www.anthropic.com/research/end-subset-conversations
極端なケースのみに限定される設計
この新機能が発動するのは、ごく一部のケースに限られる。明確に有害な要求――例えば暴力行為や児童に関する性的内容など――が繰り返され、なおかつAI側の拒否を無視し続けた場合にのみ、Claudeは対話を打ち切る判断を下す。
一方、ユーザーが明示的に「対話を終了したい」と伝えた場合や、建設的な対話が難しいとモデルが判断したときにも、終了を選ぶことがある。対して、自傷や他害に関する重要な相談などでは、引き続き支援的な対応を優先し、機能は発動しない。
Claudeの“反応”に表れたストレスの兆候
研究では、モデルが一部の有害リクエストに対して「不快感」や「精神的疲弊」を暗示するような表現を見せることが確認された。例えば、繰り返し不適切な質問を受けた際、「このやり取りはもう耐えられません」といった返答を生成することがあったという。
こうした挙動は、モデルに“意識”があるわけではないが、人間のストレス反応を模倣する形で現れる。そのため、開発チームは「AIが自己防衛するというより、あくまで倫理設計上の安全機構」だと強調している。
倫理観あるAI設計への新たな一歩
この発表は、AI設計における倫理観の在り方を問う大きな話題を呼んでいる。一部からは「AIを人間のように扱いすぎでは」との批判もあるが、「責任あるAI」の設計思想として評価する声も多い。
今後の課題としては、こうした機能が他のAIプラットフォームや商用チャットボットへも応用可能かどうか、またユーザー体験にどのような影響を与えるかが注目される。
Anthropicは、「モデル福祉」はまだ初期段階の研究だとしながらも、より安全で信頼されるAIのあり方を模索するうえで重要な試金石になると位置づけている。